インデックスとは、テーブルまたはビューの特定の列に設定する索引情報です。インデックスの作成・削除について説明しておきましょう。
- テーブルとビューの索引情報 -
データベース・エンジンは、データベース内の各テーブルのインデックスをテーブルとは別に管理し、メモリに読み込んでアクセスします。これによって、物理的なディスクに対するアクセスを減らし、レコードを高速に走査できます。
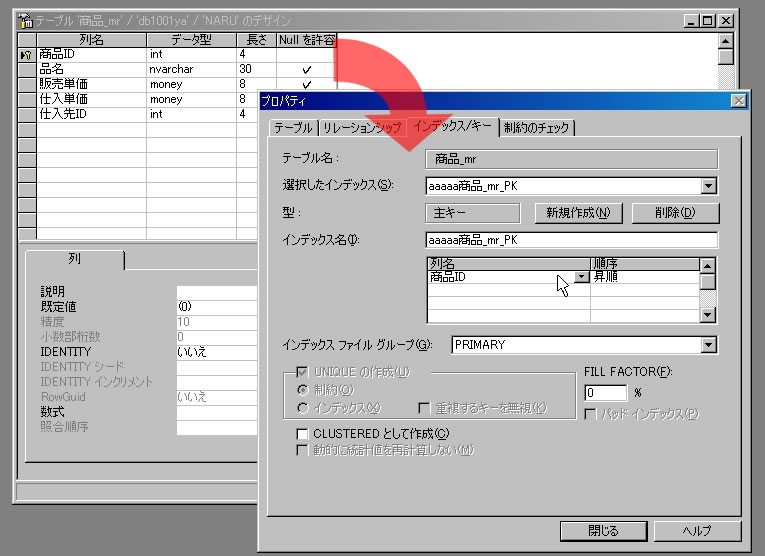
通常、インデックスはテーブルの作成時に設定します。EnterpriseManagerでは、テーブルのデザイン画面でインデックスを設定したいフィールドを選択し、コンテキストメニューから「インデックス/キー」を選択して[新規作成]ボタンをクリックすれば、選択したフィールドにインデックスを設定できます。
1つのテーブルにつきインデックスは16個まで指定できますが、1~2フィールドとするのが最も効率的です。
また、インデックスの記録順をフィールドの値の昇順にするか降順にするかも指定できます。これは、業務の目的によって、特定のフィールドを昇順に走査した方がよい場合もあれば、降順に走査した方がよい場合もあるためです。
例えば、商品や得意先のマスターテーブルに設けられたIDフィールドなら、通常は昇順で構いません。しかし、在庫数や売上金額、試験の成績などなら降順に並んでいた方が効率的な場合もあります。
- インデックスの3属性 -
インデックスには「クラスタ化インデックス/非クラスタ化インデックス」の2種類があります。また「ユニーク・インデックス」を設定することもできます。
・クラスタ化インデックス
レコードがディスクに記録される順序(実際には、最初のアクセス直前にメモリに読み込まれる順序)とインデックスを設定したフィールドの値の順序とが同じインデックスは「クラスタ化インデックス」と呼ばれます。
従って、クラスタ化インデックスは1つのテーブルまたはビューに対して1つだけ設定できます。テーブルもビューも、複数のクラスタ化インデックスを持つことはできません。 一般に、マスターテーブルのIDフィールドはクラスタ化インデックスに設定できます。また、日付や時刻に基づいて連番で生成された伝票番号なども、クラスタ化インデックスに設定できます。
・非クラスタ化インデックス
非クラスタ化インデックスは、物理的な記録順とレコードの値の順序とが異なるインデックスです。例えば、在庫マスターの在庫数フィールドや顧客の生年月日フィールドをインデックスとするような場合、これらは非クラスタ化インデックスとなります。
なお、複数のインデックスを持つビューには、必ず1つのクラスタ化インデックスを設定しなければなりません。
・ユニーク・インデックス
一意の――複数のレコードが同じ値を持たない──インデックスです。
SQL Serverでは、ユニーク・インデックスの作成時に全レコードの対象フィールドをすべて走査し、重複する値の有無をチェックします。また、INSERT命令で新たなレコードが追加されたり、UPDATE命令でフィールドの値が更新された場合も、逐次フィールドの値が重複していないかチェックします。
このとき、複数のフィールドにNULLが保持されている場合も「値の重複」とみなされ、エラーとなります。ユニーク・インデックスとするフィールドは、一般にNULLを許容しないよう設定します。
- インデックスを作成する~CREATE INDEX -
インデックスは、既存のテーブルに対して後から設定や削除ができます。本来ならCREATE TABLE命令でテーブルを作成するときに併せてインデックスも設定するべきですが、業務システムの仕様変更などに伴い、あとから設定する必要のある場合もあります。
また、CREATE VIEW命令で生成したビューに対しても、その後からインデックスを設定することになります。
インデックスを設定するにはCREATE INDEX命令を用います。書式は以下のようになります。
CREATE [UNIQUE] [CLUSTERD | NONCLUSTERED] INDEX <インデックス名>
ON <テーブル名 | ビュー名> (<フィールド名> [ ASC | DESC ])
基本は、<テーブル名 | ビュー名>で指定したテーブルまたはビューの<フィールド名>で示すフィールドに対して<インデックス名>で示す名前のインデックスを設定します。
()内の<フィールド名>に続けてASCを指定すれば昇順、DESCなら降順のインデックスが生成されます。省略すると昇順となります。
UNIQUEを指定すればユニーク・インデックス、CLUSTERDを指定すればクラスタ化インデックス、NONCLUSTERDを指定すれば非クラスタ化インデックスとなります。
UNIQUE、CLUSTERD、NONCLUSTERDは省略でき、その場合は『ユニークでない非クラスタ化(NONCLUSTERD)インデックス』となります。
- 商品マスターにインデックスを設ける -
ここではテーブル「商品_mr」の代わりに「商品_dmy」を使って例を示しておきます。
テーブル「商品_dmy」の「商品ID」フィールドにユニークなインデックスを昇順で設定するなら、以下のようなSQLを記述します(ex04.sql)。
CREATE UNIQUE INDEX idx_ItemId
ON 商品_dmy (商品ID ASC)
テーブル「商品_dmy」はこれまでの操作で既にデータベースに存在しているはずですが、もし存在していなければ以下のSQLを実行して作成してください。
SELECT * INTO 商品_dmy FROM 商品_mr
- インデックスを削除する~DROP INDEX -
作成したインデックスを削除するには、DROP INDEX命令を使います。書式は以下のようになります。
DROP INDEX <テーブル名 | ビュー名>.<インデックス名>
先にテーブル「商品_mr」の「商品ID」フィールドに作成したインデックス“idx_ItemId”を削除するなら、以下のようなSQLを記述します(ex05.sql)。
DROP INDEX 商品_dmy.idx_ItemId
『商品_dmy.idx_ItemId』のようにテーブル名とインデックス名は「.」でつなぎます。注意しましょう。
なお、インデックスは作成するか削除するかしかできないため、ALTER命令は適用されません。作成したインデックスの属性(UNIQUE、CLUSTERDかNONCLUSTERDか)を変更するには、一旦DROP INDEX命令でインデックスを削除してからCREATE INDEX命令で作成し直します。
- インデックスの作りすぎは非効率 -
インデックスを作成すると、テーブルとは別にインデックスのための領域が設けられます。それがメモリに読み込まれ、アプリケーションからのSQLなどによってテーブルが走査されるときに、データベース・サーバーはメモリ上のインデックス情報にアクセスして高速なレコード検索を行います。
そのため、処理を速めようと1つのテーブルにたくさんのインデックスを設けると、逆にサーバーの負荷が増えて効率が低下する場合があります。一般に、インデックスはテーブル1つにつき1~3個程度としておきます(先述したように、2個までが効率的です)。
「商品_mr」や「仕入先_mr」などのマスターテーブルでは、関連付けのためにIDフィールドを主キーとします。この主キーフィールドをユニーク・インデックスとしておくと、複数のテーブルを関連付けた複雑なSQLから、高速にレコードを見つけ出せるようになります。
それ以外のフィールドでは、例えば氏名や会社名の読みをユニークでない非クラスタ化インデックスとして、読みによる検索・抽出を効率化することが考えられます。
また、受注・販売や仕入れ状況を記録するテーブル「受注ヘッダ」「受注明細」や「仕入ヘッダ」「仕入明細」の「伝票番号」フィールドは主キーではありませんが、これらにインデックスを設けておけば、関連付けを行ったSQLの処理が速くなります。伝票番号のような連番の値は、その仕様によってはユニークなクラスタ化インデックスに設定できます。
ただ、氏名や伝票番号による検索や並べ替えの処理を頻繁に行わないのなら、わざわざインデックスを作る必要はありません。インデックスを設けていると、レコードを追加・更新・削除するたびにインデックス領域も走査されるため、先述したようにサーバーの負荷が増え、かえって逆効果となってしまいます。
処理効率は、単に1つのテーブルや関連付けからだけではなく、データベース全体、サーバー全体の構造を見渡して考えなければなりません。
 |