集計の基本は、同じ種類に属する情報を一括りにすることです。これをグループ化(グルーピング)と呼びます。
- GROUP BY句 -
テーブルをグループ化するにはSELECT命令にGROUP BY句を用います。書式は以下の通りです。
SELECT <フィールド>
FROM <テーブル>
GROUP BY <キーフィールド>
<テーブル>で示したテーブルから<キーフィールド>で示したフィールドの値が同じレコードがまとめられ、<フィールド>で指定したフィールドが取り出されます。<キーフィールド>と<フィールド>は同じでなければなりません。
- 商品を仕入先でまとめる -
まずは、商品マスター「商品_mr」に記録された商品の情報を仕入先ごとにまとめてみましょう。商品_mrのフィールド構成は次のようになっていました。
商品ID 品名 販売単価 仕入単価 仕入先ID
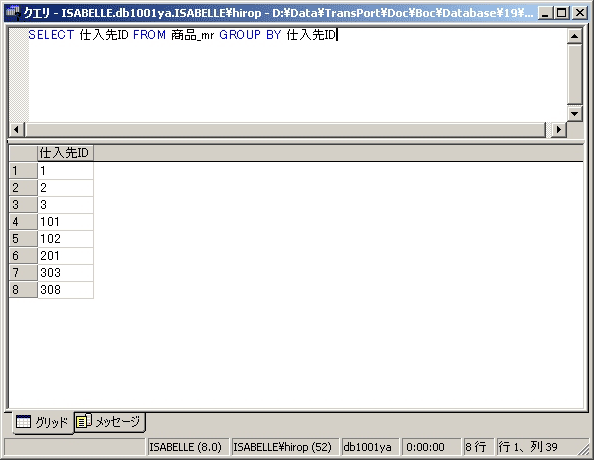
仕入先ごとにまとめるには「仕入先ID」をキーフィールドにしなければなりません。単純なSQLとして、以下のような形が考えられます。
SELECT 仕入先ID
FROM 商品_mr
GROUP BY 仕入先ID
クエリアナライザで実行すると、画面1のような結果が得られます。
- キーフィールドの列挙 -
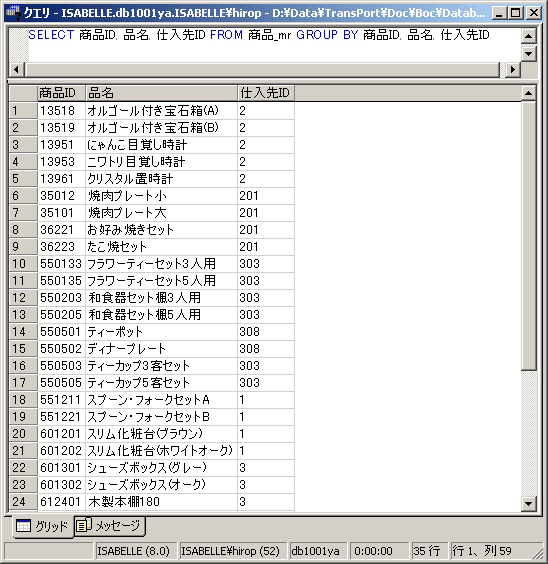
上の状態では「8件の仕入先がある」ということくらいしか分かりません。「どの商品がどの仕入先なのか」もう少し分かるようにしてみましょう。
SELECT 商品ID, 品名, 仕入先ID
FROM 商品_mr
GROUP BY 商品ID, 品名, 仕入先ID
このように、キーフィールドには複数のフィールドを「,」で列挙して指定できます。その場合、リストの左から順にグループ化が行われますが、この例では「商品ID」と「品名」は他のレコードと重複する値がないため「仕入先ID」の値だけでグループ化され、画面2のような結果となります。
- ORDER BY句による並べ替え -
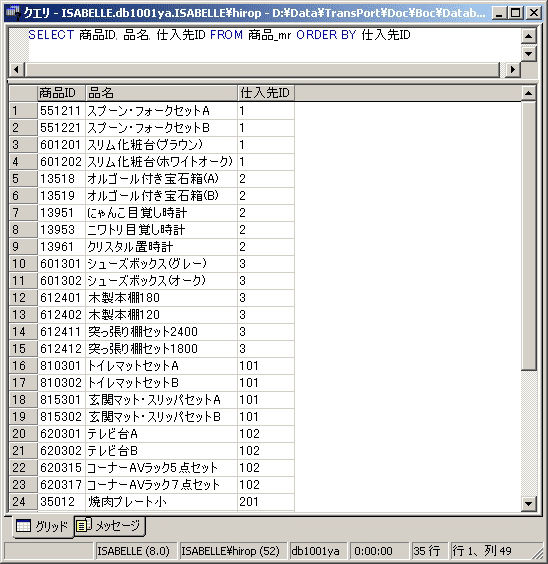
「仕入先ID」だけを表示させるとレコードが完全に束ねられ、抽出結果は仕入先の件数分となりました。しかし、他のレコードを重複しないフィールドを指定すると、抽出されるレコード件数は元のテーブル(商品_mr)の件数と同じになります。
ただ、レコードが同じ仕入先IDを持つもの同士で固められるため、「どの仕入先から何を仕入れているか」が分かりやすくなります。しかし、このような結果を得るだけなら、ORDER BY句を使った並べ替えでも同じことができます。
SELECT 商品ID, 品名, 仕入先ID
FROM 商品_mr
ORDER BY 仕入先ID
- グループ化と整列 -
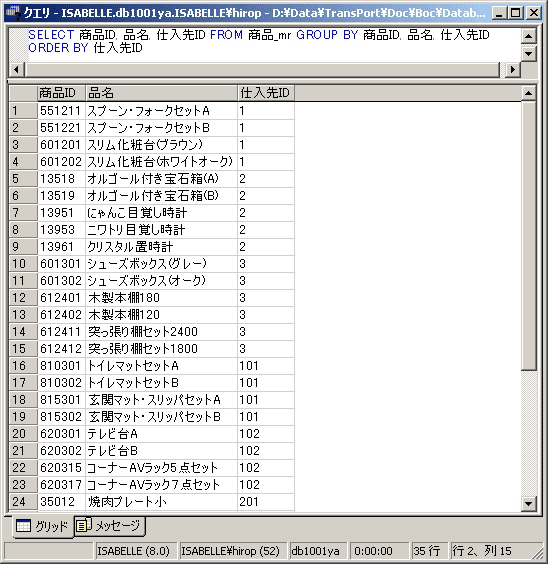
むしろ、こちらの方が仕入先IDの昇順に並ぶので、見た目にも分かりやすい結果となります。GROUP BY句によってグループ化した結果をORDER BY句で並べ替えることもできます。
SELECT 商品ID, 品名, 仕入先ID
FROM 商品_mr
GROUP BY 商品ID, 品名, 仕入先ID
ORDER BY 仕入先ID
結果は、先にORDER BY句だけを使った場合とまったく同じになります。これは、元のレコードがあらかじめ「商品ID」の昇順に並んでいるためでもありますが、これだけならわざわざグループ化する意味はありません。グループ化は集計の機能と相まって真価を発揮します。
 |
|
|