SELECT命令の動作は日本語に直訳して「選択」と呼ばれますが、実際には「抽出」と言った方が正確です。データベースの入門書などでは、レコードの「検索」と「抽出」が混同されているケースが時々ありますが、単に言葉の問題ではなく、システム開発の面からも両者の違いは重要です。
- SELECTは抽出命令 -
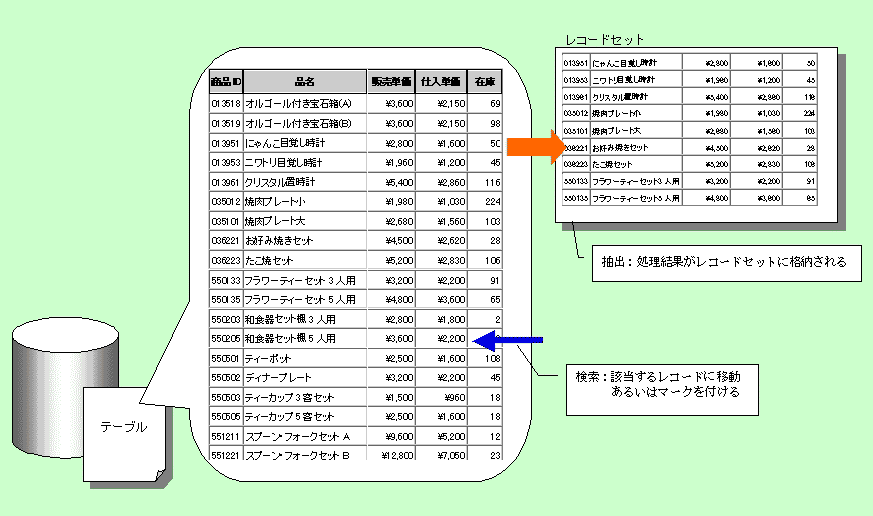
SELECT命令によってテーブルから取り出されたレコード群は、レコードセット(行セット)としてSQLを発行したクライアント側のプログラムに渡されます。基本的には、レコードセットはSQLを発行したプログラムの稼働するクライアントのメモリまたは一時ファイルの中に生成されます。ストアドプロシージャやビューなどデータベース側の処理として発行された場合は、サーバーのメモリに生成される場合もあります。
どちらに生成された場合も、レコードセットはテーブルに記録されているレコードとは――論理的なつながりを維持しつつも、実体としては――まったく別の存在となります。ADOなどのコンポーネントを介してデータベースを操作した場合、レコードセットはオブジェクト(Recordsetオブジェクト)として扱われます。また、コンポーネントを構成するオブジェクト群の継承によって、レコードセットへの参照(実際にはメモリ上のアドレス)があるオブジェクトのプロパティとして保持される場合もあります。
いずれにせよ、レコードセットはテーブル内のレコードそのものではなく、そこから切り離された単独の存在です。つまりSELECT命令は、元のテーブルからレコード群を取り出して――抽出してくる命令ということです。
- 検索はレコードセットを生成しない -
一方「検索」という表現は、SELECT命令で抽出されたレコード群――レコードセットの中から(あるいは元のテーブルから直接)、一定の条件を満たすレコードを「示す」行為です。これはRDBMSやSQLの機能ではなく、レコードセットをオブジェクトとして扱うコンポーネントやプログラムに実装された機能です。
レコードセットを扱うコンポーネントには、現在注目している1件のレコードを指し示す値(プロパティ)が用意されています。Accessなどで言われる「カレントレコード」の概念は、この値(レコード・ポインタなどの名称で呼ばれます)の示しているレコードということです。
検索処理では、この値が特定のレコードを指し示す――特定のレコードがカレントレコードとなる――だけです。あるいは、条件を満たす複数のレコードに、何らかのマークを付ける場合もあります。どちらの場合も、SELECTによる「抽出」のように元のテーブルやレコードセットから切り離された別のレコードセットが生成される訳ではありません。
つまり、レコードセットの中で何らかの変化が起こる訳ではなく、それを扱うコンポーネント(=オブジェクト)のあるプロパティの値が変化するだけなのです。
- 違いを意識しておこう -
データベースを扱うプログラムの中で行われる検索処理も、SELECT命令によって抽出されたレコード群に対して、その中の1件または複数のレコードを取得するだけであって、新たなレコードセットが生成されたり、レコードセットの内容が書き換えられたりする訳ではありません。
従って、検索されたレコードは元のレコードセットに保持されているレコードそのものです。「レコードを絞り込む」といった表現をするとき、それが実際にはレコードセットの生成を意味するSELECT命令の発効なのか単なる検索なのかでは、処理内容に大きな違いが生じます。
SELECT命令による「抽出」とプログラムによる「検索」とは、まったく異なる動作であることを意識しておきましょう。
なお、業務システムなどで特定のレコードをSELECT命令で抽出する処理に「商品の検索」などという名称を付けている場合がありますが、これはユーザーインターフェイス上の問題であり、アプリケーションの内部仕様や開発者の考え方とは別のものです。このあたりの違いも意識しておきましょう。一般のユーザーには、「抽出」や「選択」より「検索」の方がイメージをつかみやすいのは、言うまでもありません。
SQLの出発点はSELECT命令です。ここでレコードを抽出するところから、様々なデータベース処理へと発展していきます。SELECT命令の発行によって生成されるレコードセットの概念が、データベース操作には非常に重要です。サンプルを使って、いろいろ試してみてください。
- サンプルデータの使い方 -
記事の中で紹介したSQLを実際に試していただくために、サンプルのデータベースを用意しました。利用するには、SQL Server 2000がインストールされて稼働していることが大前提です。MSDE(2000のサブセットである“Microsoft Desktop Engine”)でも構いません(SQL Server 7.0では試していません)。
圧縮ファイルは2個あります。
| ・ |
database03.lzh
サンプルのデータベースです。SQL Serverに登録して使います。 |
| ・ |
examples03.lzh
今回の記事で取り上げたSQLのサンプルです。クエリアナライザなどで開いて実行できます。 |
サンプルデータベース(database03.lzh)の使い方
database03.lzhを解凍すると、以下の4つのファイルが生成されます。
| ・ |
db1001ya-1.mdf |
| ・ |
AddExampleDb.sql |
| ・ |
DelExampleDb.sql |
| ・ |
db1001ya-1.mdb |
| ・ |
db1001ya-1.mdf
SQL Serverのデータベースファイルです。SQL Serverのデータ保存場所(“C:\MS SQL Server\Data”、“C:\MSSQL\Data”など)にコピーしてください。 |
| ・ |
AddExampleDb.sql
SQL Serverにサンプルデータベースを登録するためのスクリプトファイルです。mdfファイルの場所は“C:\MSSQL\Data”となっています。そこに上記の“db1001ya-1.mdf”を保存し、クエリアナライザでこのスクリプトを開いて実行すれば、データベースが“db101ya”という名前で登録されます。
スクリプトは以下のようになっているので、mdfファイルを異なる場所に保存したときは、アンダーラインの箇所を適切なパスに書き換えてください。 |
CREATE DATABASE db1001ya
ON PRIMARY (FILENAME = 'C:\MSSQL\Data\db1001ya-1.mdf')
FOR ATTACH
GO
| ・ |
DelExampleDb.sql
登録したデータベース“db1001ya”をSQL Serverから削除するスクリプトです。クエリアナライザでこのスクリプトを開いて実行すれば、サンプルのデータベースが削除されます。
スクリプトは以下の1行です。
sp_detach_db db1001ya
|
| ・ |
db1001ya-1.mdb
Access 2000のデータベースです。Accessで開いてアップサイジング・ウィザードを起動すれば、SQL Serverのデータベースに変換できます。クエリアナライザなどの操作が面倒な方は、こちらの方法を使ってください。
SQL Server 7.0(または7.0のサブセットである“Microsoft Data Engine”)の場合も、Accessからのアップグレードならデータベースを登録できます。 |
 サンプルファイル (LZH形式 158 KB) サンプルファイル (LZH形式 158 KB)
クエリファイル(examples03.lzh)の使い方
examples03.lzhを解凍すると、ex01.sql~ex06.sqlの6個のクエリファイルが生成されます。それぞれ、クエリアナライザで開いて実行できます。これを実行するためには、先にサンプルデータベース“db1001ya”が、SQL Serverに登録されていなければなりません。
サンプルファイル (LZH形式 768 B)
 |
|
|