第31回
データ構造(10)~構造体をポインタでつなぐ
構造体とsizeof演算子malloc関数で構造体のためのメモリを確保するとき、sizeof演算子で構造体の占有するメモリのバイト数を調べました。ここで、ちょっと疑問が湧いてきます。構造体を構成する各メンバの型は定義時に明らかになっているのですから、それらのサイズを合計すれば、わざわざsizeof演算子を使わなくても構造体の占有するバイト数は分かるはず──という疑問です。サイズ=メンバの合計……とは限らない例えば、以下のように宣言した構造体があるとします。short int型は2バイト、要素数9(8+1)のchar型配列は9バイトなので、この構造体の占有するバイト数は「2+9=10」で11バイトとなるはずです。struct _box {
short int id;
char name[8+1];
};
ところが、必ずしも計算通りにいく訳ではありません。 2種類の構造体で試す以下の2つの構造体が占有するサイズをsizeof演算子で調べてみましょう。struct {
short int id;
char name[8];
} box1;
struct {
short int id;
char name[8 + 1];
} box2;
box1はshort intと要素8個のchar型配列なので、10バイトとなります。box2はchar型配列の要素が1個増えているため、11バイトを占有するはずです。 実際にそうなるかどうか、リスト3のような簡単なプログラムで試してみましょう。LSI-C 86でコンパイルして実行すると、以下のように表示されます(ex3102a.exe)。 box1 = 10, box2 = 11 リスト3:2つの構造体の占有サイズを調べる(ex3102.c) #include <stdio.h>
int main(void)
{
struct {
short int id;
char name[8];
} box1;
struct {
short int id;
char name[8 + 1];
} box2;
printf("box1 = %d, box2 = %d\n", sizeof(box1), sizeof(box2));
return (0);
}
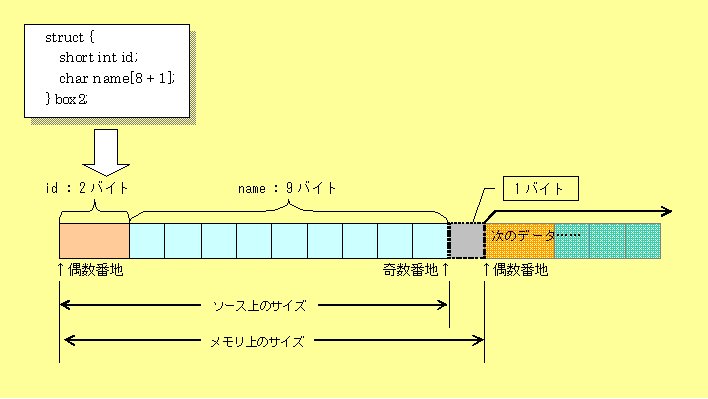
1バイト多くなる?!今度は、Visual C++で同じソースをコンパイルしてみます。このコラムで既に何度か書いていますが、Visual C++ではプロジェクトで「Win32 コンソールアプリケーション」を選択し、main関数の代わりにint _tmain(int argc, _TCHAR* argv[])を定義します。中に記述するソースは同じです。 これを実行すると、 box1 = 10, box2 = 12と、表示されます。(ex3102b.exe)char型配列の要素が1つ多いbox2の占有サイズが11ではなく12となり、1バイト増えていることが分かります。 処理系によってサイズが異なる多くのコンパイラは、データを2バイト(=1ワード)単位で揃えようとします。これは、多くのCPUが『奇数番地から始まるデータより偶数番地から始まるデータの方が効率的に扱える』ようになっているためです。そのため、box2のようにchar型配列の要素が奇数個の場合、さらに1バイトの「何もない領域」を追加して割り当て、次にメモリ上に確保されるであろうデータが偶数番地から始まるよう調整するのです。 これを「パディング」と呼び、構造体でなくてもchar型変数を1個宣言したような場合や、奇数個の要素を持つchar型配列を宣言した場合にも、その次に1バイトのパディングが行われたりします。 こういった動作はコンパイラによって違うため、LSI-CとVisual C++とで結果が異なったのです。 |
Copyright © MESCIUS inc.