データベースに限らず、文字列というデータ型の扱いは数値に比べて複雑になります。値の大小だけではなく、一部が同じある――といったパターンマッチングが適用できるためです。LIKE演算子の扱いについて、もう少し説明しておきます。
- 完全合致 -
ワイルドカードを使わない場合、フィールドの値が指定した文字列に完全に合致するレコードだけが抽出されます。
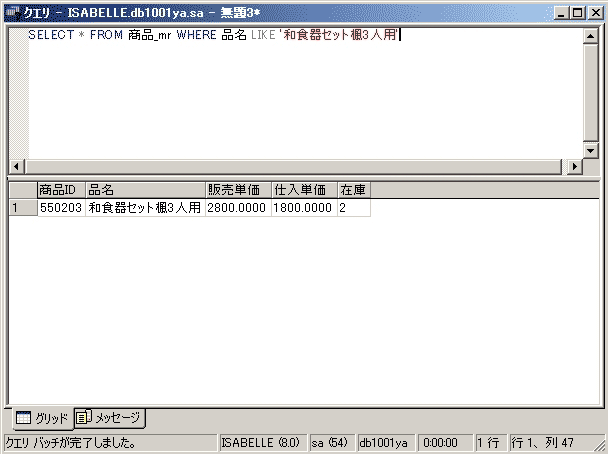
例えば以下のようなSQLを記述すれば、「品名」フィールドの値が“和食器セット楓3人用”となっている1件のレコードだけが抽出されます。
SELECT * FROM 商品_mr WHERE 品名 LIKE
'和食器セット楓3人用'
↑文字列は''で囲む
(レイアウトの都合上、改行して表記されています)
ただ、実際の処理では、品名が完全に分かっているようなケースはまれです。商品を種類によって、あるいは社員名簿を所属によって分類し、特定の種類の商品や特定の部署の社員だけを抽出するような場合に用いることになるでしょう。
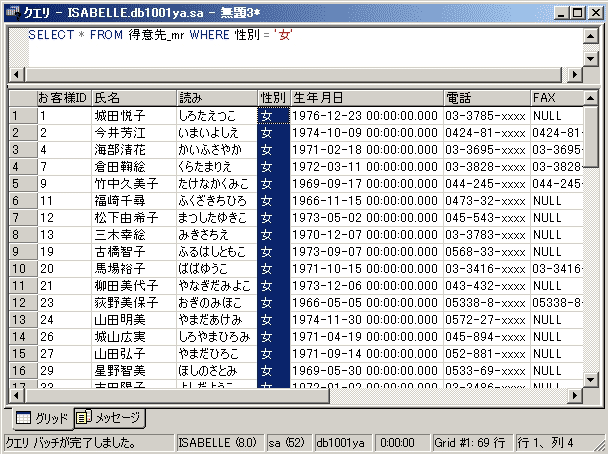
サンプル・データベース中の「得意先_mr」テーブルでは、「性別」フィールドに“男”または“女”という文字列が格納されています。このテーブルから「女性のレコードだけ」を抜き出すなら、以下のようなSQLを記述します。
SELECT * FROM 得意先_mr WHERE 性別 LIKE '女'
このような完全合致を求める条件式では、LIKE演算子の他に比較演算子の「=」も使えます。従って、上のSQLは以下のようにしても同じです。
SELECT * FROM 得意先_mr WHERE 性別 = '女'
- 一部合致 -
LIKE演算子は、ワイルドカードを使って文字列の中の一部が合致するレコードを抽出する処理に用いるのが一般的です。いわゆる「あいまい検索」です。
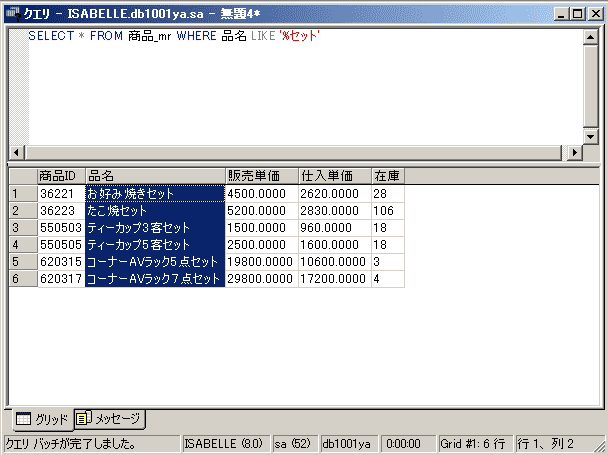
「商品_mr」テーブルから「~セット」という商品名のレコードを探したい場合は、以下のようなSQLを記述します。
SELECT * FROM 商品_mr WHERE 品名 LIKE '%セット'
「%」は「複数の任意の文字」に合致するので、「お好み焼きセット」「ティーカップ5客セット」などなど、「品名」フィールドの値の最後が“セット”となっているすべてのレコードに合致します。
実行結果を見れば分かるように、上記のSQLでは「突っ張り棚セット2400」や「トイレマットセットA」など文字列の途中に“セット”の文字列が入っているレコードは合致しないことになるため、抽出されません。
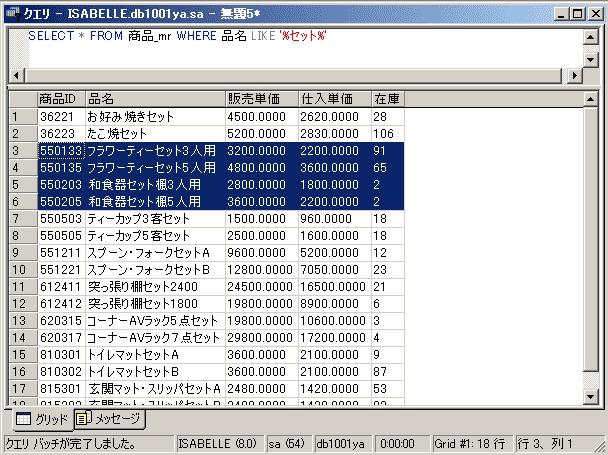
これらも抽出したい場合には、以下のようなSQLにします。
SELECT * FROM 商品_mr WHERE 品名 LIKE '%セット%'
“セット”という文字列の後ろにも「%」を記述することで、フィールドの値の途中に“セット”という文字列の入っているレコードも抽出されます。「%」は「0個以上の文字列」に合致するため、「お好み焼きセット」のように“セット”の後ろに何もない文字列(=後ろに0個の文字列があると見なされる)も合致したことになります。
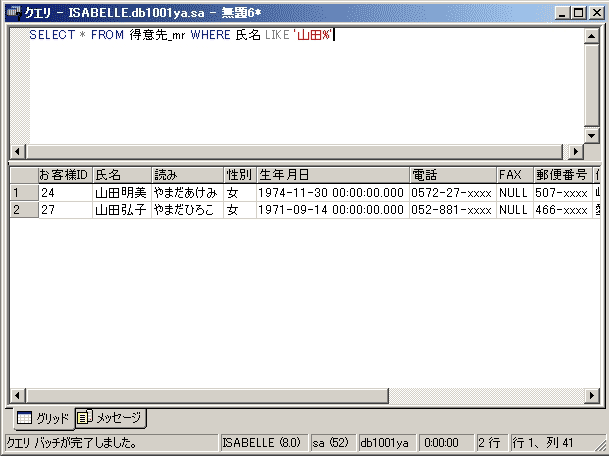
「得意先_mr」テーブルなどのような名簿では、「氏名」や氏名の「読み」に対してあいまい検索を実行できます。例えば「山田~」さんなど姓だけが分かっている場合、以下のようなSQLで対処できます。
SELECT * FROM 得意先_mr WHERE 氏名 LIKE '山田%'
- 範囲を指定 -
文字の範囲を指定して、その中のどれかにあてはまるレコードを抽出する場合は、文字範囲を[ ]で囲み、先頭と最後を「-」でつないで指定します。この指定方法は、複数の任意の文字列にあてはまる「%」と組み合わせて使うことになります。
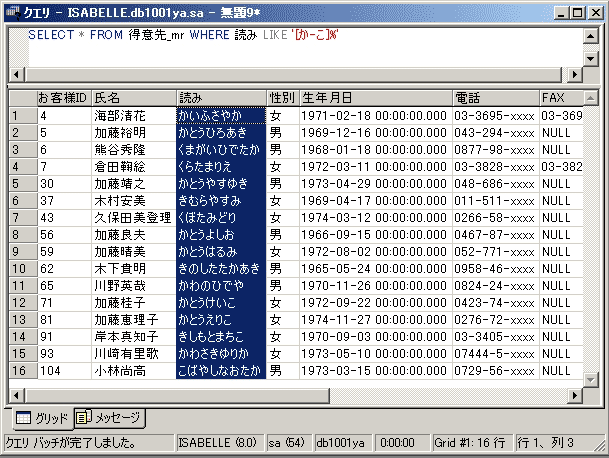
例えば、「得意先_mr」テーブルから「氏名の読みが五十音の“か行”で始まる人」を抽出するなら、以下のようなSQLを記述します。
SELECT * FROM 得意先_mr WHERE 読み LIKE '[か-こ]%'
[か-こ]と指定することで、フィールドの値が「かきくけこ」のどれかで始まることを、続く「%」でそれ以降の文字列が何文字のどんなものでも合致することを指定できます。
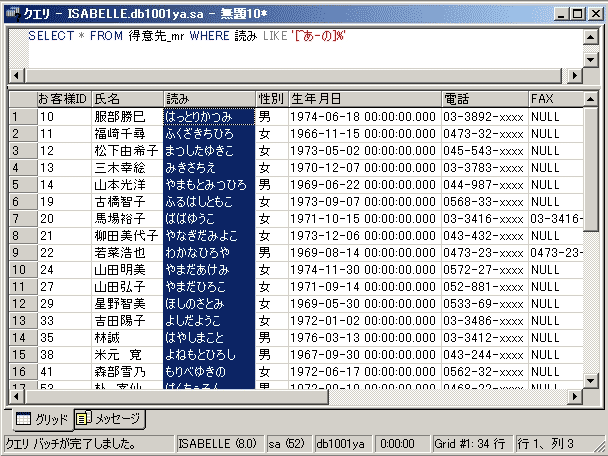
[ ]内の範囲の先頭に「^」を付けると、「それ以外(NOT)」を意味します。「得意先_mr」テーブルから「氏名の読みが“はまやらわ”で始まるレコードを抽出するなら、通常は以下のようなSQLになります。
SELECT * FROM 得意先_mr WHERE 読み LIKE '[は-ん]%'
上と同じ結果は、以下のSQLでも得られます。
SELECT * FROM 得意先_mr WHERE 読み LIKE '[^あ-の]%'
「あ~の」で始まるレコードを「除外」することで、残る「は~ん」で始まるレコードだけが対象となります(「ん」や「を」で始まる氏名は存在しませんが)。些細なことですが、一般的な姓名は「あ~の」までの範囲より「は~ん」までの範囲に収まる方が少ないので、[^]を使った後者の方が走査対象のレコードが少なくなり、結果として(わずかながら)処理が速くなります。
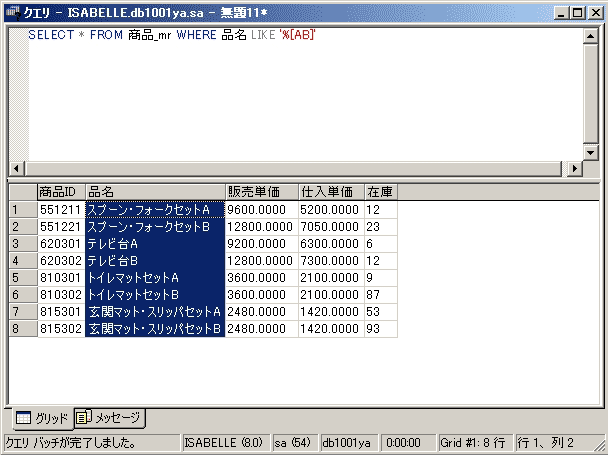
[ ]内に文字を列挙すれば、その中の文字が含まれているレコードが抽出されます。「商品_mr」テーブルから「品名」の最後に“A”または“B”と付いているレコードだけを抽出するなら、以下のようなSQLを記述します。列挙する文字の間に区切りの「,」は不要です。
SELECT * FROM 商品_mr WHERE 品名 LIKE '%[AB]'
 |
|
|